
Recently, I went to a running hot-pot restaurant with a friend. Ingredients kept passing us on small tracks, and almost all of them looked tempting. The real challenge was not finding appealing options. It was deciding what actually deserved our appetite.
Product development often runs into the same problem. Teams say they want to be data-informed. In practice, that usually means working with a mix of analytics, stakeholder input, support tickets, business pressure, and user feedback. All of that can help. The difficulty starts when those inputs have to become a decision about what should happen next.
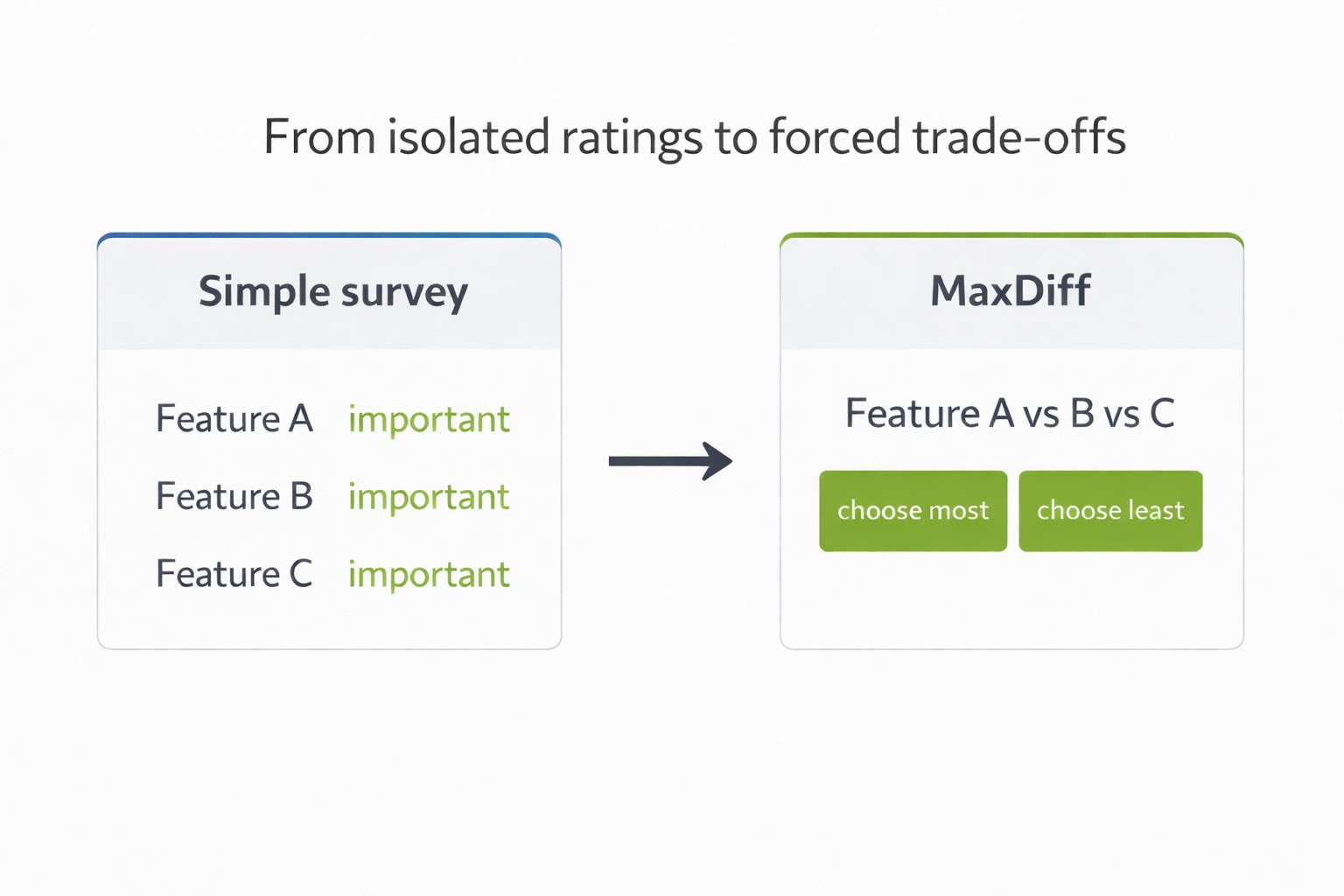
This is often the moment when teams reach for a standard survey. On the surface, that seems sensible. Ask users to rate a list of features on a Likert scale and you get numbers back. That kind of data can be useful, but it is often too weak for a prioritisation decision.
Where simple surveys reach their limit
A rating survey asks people to judge each feature in isolation. That is a long way from how product decisions are actually made. Several options can honestly sound important when they are viewed one by one, without cost, compromise, or competition. In a spreadsheet, the result looks structured. In a roadmap discussion, it often changes very little. The team still has to decide what deserves priority, even though many options now carry a respectable score.
Prioritisation is a trade-off problem. It lives under constraint. Time is limited, capacity is limited, and product teams rarely get to build everything they would like to build. If the research design does not reflect that pressure, the result will usually be broad approval without enough differentiation.
A simple example makes the difference easier to see. In a food delivery app, several things can sound useful at the same time: clear delivery updates, fast checkout, saved favourites, or transparent fees. None of these is meaningless, and not all of them are “features” in the narrow product sense. Some are closer to experience qualities. That is exactly the point. MaxDiff becomes more revealing once people have to choose which of these would matter most in deciding whether to use the app. It does not just show that several aspects sound good in isolation. It helps uncover which ones carry more weight when they compete.
That is why method choice matters in product work. A broad attitude check is one thing. A prioritisation exercise is another.
What MaxDiff changes
This is where two methods from market research become surprisingly useful in product work: MaxDiff, short for maximum difference scaling, and Conjoint analysis.
MaxDiff introduces decision pressure. Instead of asking whether a feature is generally liked, it asks respondents to choose which option matters most and which matters least from smaller sets, repeatedly. That shift may seem minor, but it changes the quality of the signal.
Moreover, MaxDiff is not limited to direct product features. It can also be used to compare benefits, claims, messages, or user-facing experience qualities, as long as the list is framed as a coherent set of stand-alone items rather than a mixture of different abstraction levels. Qualtrics’ guidance is explicit that MaxDiff works best with mutually exclusive items that act as offerings in and of themselves.
So, a feature can sound attractive when viewed alone and still lose when placed next to something users consider more valuable. In ths regard, MaxDiff gets closer to two realities at once. It reflects the reality of product work, where features compete for limited roadmap space. It also reflects the reality of user priorities, where not everything that sounds helpful is equally valuable in practice.
That matters because teams are rarely deciding between a good feature and a bad one. More often, they are deciding between several plausible options. A method that exposes relative value is far more useful than one that simply confirms broad approval.
Why user context still comes first
Even with a better prioritisation method, context still matters. Product decisions often suffer less from a lack of input than from the fact that the input arrives at different stages of the journey and answers different questions.
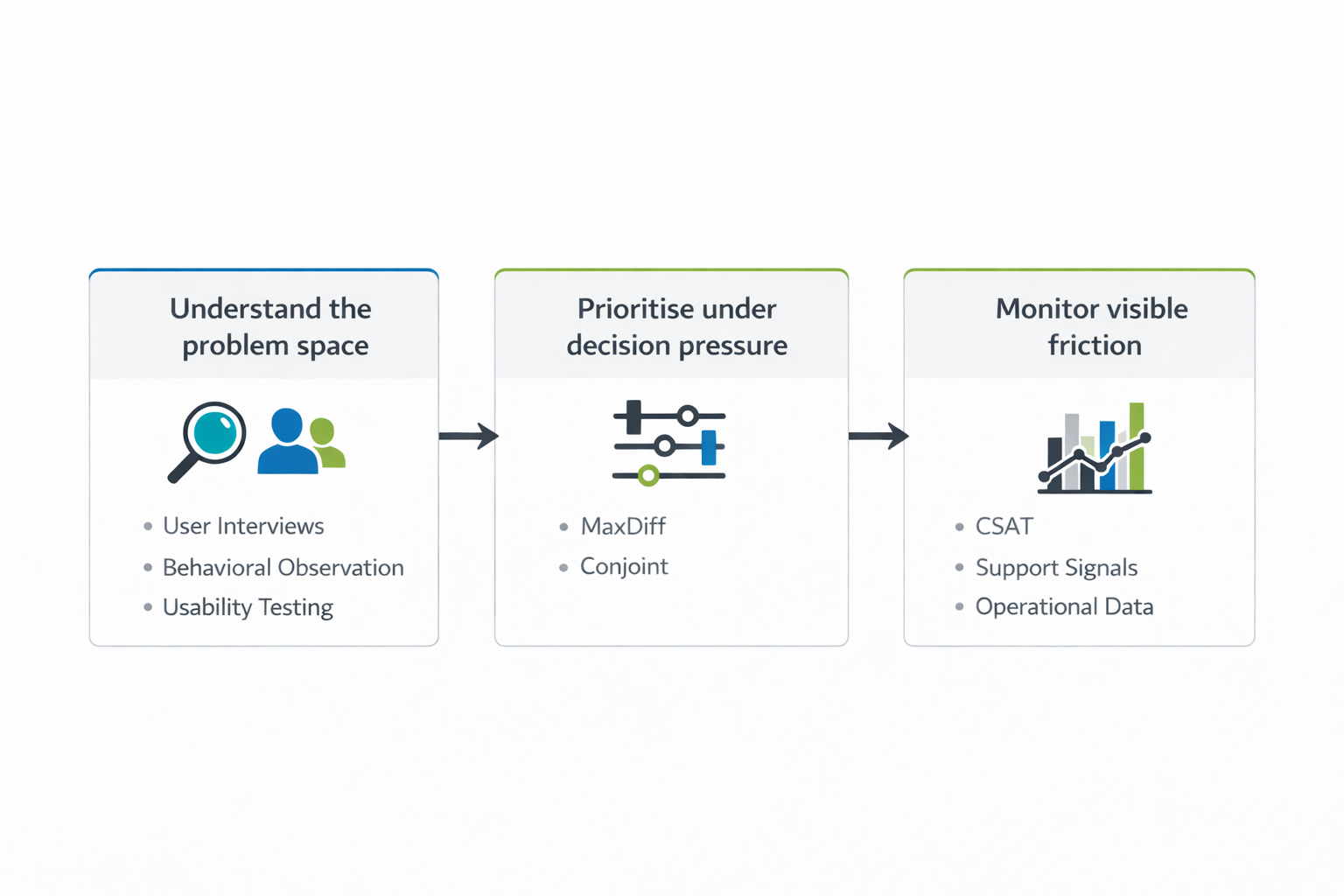
Here, qualitative research has an important place early on. Contextual observation, usability testing, and interviews grounded in real tasks can reveal friction long before it becomes visible in operational data. They help teams see where users hesitate, what they misunderstand, what they expect, and what quietly makes an experience harder than it needs to be.
By the time a user leaves a poor CSAT rating or contacts support, the issue has usually already happened. These are useful signals, but they are late ones. They show where frustration became visible enough to measure. They can tell a team that the journey broke down, but they are much less reliable when the question shifts to what should be prioritised next.
I touched on that in my earlier CSAT article as well. A metric can be very good at showing that something went wrong, while being much weaker at showing what deserves attention first.
That is why I do not see these methods as competitors. They do different work. Qualitative research helps teams understand the problem space before friction hardens into dissatisfaction or escalation. CSAT and support signals help monitor where the experience is already producing visible pain. MaxDiff becomes useful when the team has enough context to compare options and needs a more disciplined way to decide what matters more.
In real product work, this is less a theoretical debate than a practical one. Teams rarely have unlimited time, budget, or influence. The useful question is which method gives the clearest decision support for the problem in front of the team.
Where Conjoint fits
Conjoint sits close to MaxDiff, but it answers a different question.
MaxDiff is strongest when the team needs a clearer view of comparative importance across a set of individual items. Conjoint becomes more useful when the decision is about combinations. Products are rarely experienced as isolated features. People encounter bundles of choices, capabilities, service levels, pricing structures, and trade-offs. Conjoint allows teams to model that more directly.
This matters when the real question is not simply which feature matters most, but which combination is strong enough to create value. A team may want to understand whether users would accept a slower experience if it includes reliable human handover. Another may want to know which bundle of features is strong enough to justify a premium offer. In cases like these, isolated ratings stay shallow. Conjoint is better suited because it reveals how attributes perform when they are packaged together.
A stronger basis for product decisions
This is where UX becomes useful beyond discovery work. It can also improve product decisions by making trade-offs more visible and harder to ignore.
That matters in environments where opinions are strong, delivery pressure is constant, and the loudest voice can easily become more influential than the clearest evidence. Methods like MaxDiff and Conjoint do not solve that on their own, but they can shift the discussion. They turn vague approval into relative priority. That makes it easier to see what should carry more weight once choices start competing for space.
The certainty trap
Many prioritisation discussions drag on because the research input was never designed for prioritisation in the first place. Teams ask methods to answer a harder question than they were built to handle. Then they wonder why the results feel polite, broad, and inconclusive.
What product teams often need is not another long list of things that sound useful. They need a better basis for deciding what deserves to come first. Methods like MaxDiff and Conjoint can help create that basis, but they do not remove uncertainty altogether.
They still depend on how well the attributes are defined, how carefully the study is framed, and how honestly the results are interpreted. Even so, when the challenge is prioritisation, they usually provide a clearer view of trade-offs than a simple rating survey can. In product work, the options keep coming, but capacity does not.
When to use which method
Use MaxDiff when the team needs to prioritise a coherent list of comparable items. Use Conjoint when the decision is about bundles or configurations rather than single items. In both cases, most of the difficulty sits upstream: defining the right items, the right audience, and a task that people can complete without confusion or fatigue. MaxDiff works through repeated best-worst choices from smaller sets, while Conjoint is built around choices between combined offers or packages.
Want to go deeper?
Here are four useful starting points if you want to explore the methods in more detail:
- Qualtrics introduction on MaxDiff
- Qualtrics whitepaper on MaxDiff for an even deeper dive
- Sawtooth introduction on Conjoint
- Sawtooth on MaxDiff vs. Conjoint
This article was created with Generative AI support.
